CAREERS
The future of the open internet starts with you
And the next step in your career starts at The Trade Desk. Find out what kind of impact you can make.
Why come to work at The Trade Desk?
We invite ambitious people everywhere to join us in shaping the future of advertising — whether you’re looking for an opportunity to work with the world’s biggest brands, help innovate our industry-defining platform, or anything in between. And while we’ve achieved some amazing things with our technology, our people will always be our greatest asset. When you join The Trade Desk, you’re entering an environment built on empathy, collaboration, and ownership.
The principles that guide our growth
Making an impact
We’re committed to shaping the future of advertising for the benefit of the entire industry, not just a few big tech platforms. We believe the contributions of individuals have the power to change the entire industry. Which is why we encourage all our employees to get involved in as many parts of the business as possible. Because the next great idea can come from anywhere.
Entrepreneurial spirit
We’re leading the industry by fostering its next generation of leaders. Here, curiosity isn’t just appreciated, it’s rewarded. Because curiosity is the launch pad for innovation. Our people embrace the growth mindset and the passion to learn — but more importantly, they own what they do. Making mistakes is part of innovation. Letting them slow you down isn’t.
Commitment to growth
As more brands and agencies shift their budgets away from social media and search, we’ve cemented our role as a leader and innovator for advertising on the open internet. We constantly push the boundaries of what’s possible, not just for our business and our clients, but for our people as well. And as our company grows, we invite our employees to grow with it.
What we do at The Trade Desk
Learn how our omnichannel platform helps advertisers connect every important moment along the marketing journey, so they can reach their best customers, and millions of new ones, right when it matters.
Learn more about our teams
Wondering what kind of role is right for you? Learn more about what makes our teams unique — there’s something for everyone.

A more rewarding life, at work and at home
We’re passionate about what we do and the people who help us do it. That’s why we offer a wide range of perks and benefits to all our employees across the globe.

We embrace inclusion and belonging in everything we do
We believe that a diverse, collaborative, and connected team can help everyone succeed.

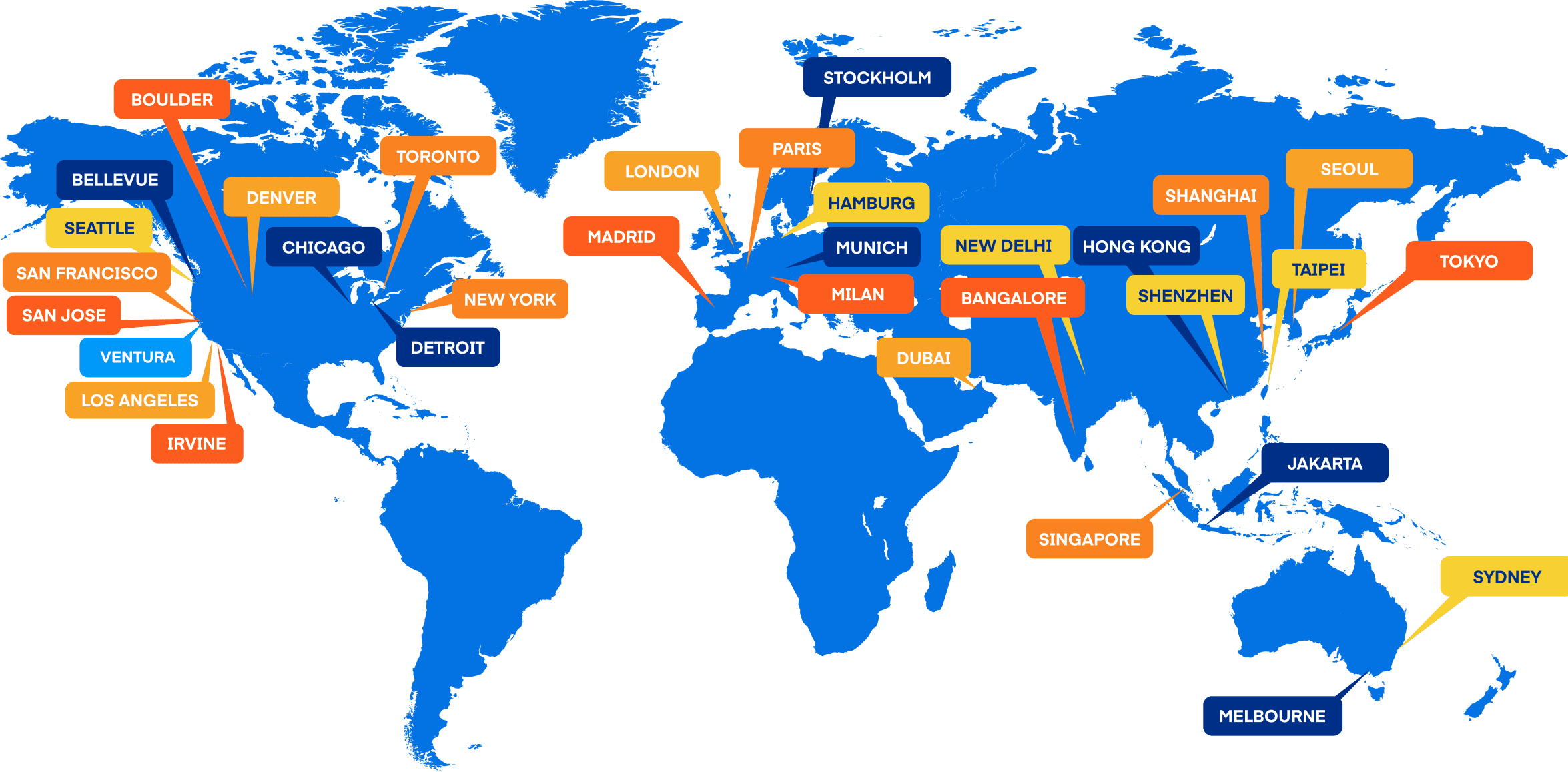
Making an impact around the world
From Los Angeles to London, Hong Kong to Hamburg, our offices span the globe — offering opportunities across the world.